


เผื่อได้ลุ้นตั๋ว UCL “คลอปป์” กระตุ้น “ลิเวอร์พูล” เดินหน้าต่อ หลังบุกปราบ เวสต์แฮม

เผื่อได้ลุ้นตั๋ว UCL R […]
สาวเชื่อหมอในเน็ต “กินน้ำร้อนแก้ปวดท้อง” ทำมาครึ่งปี สุดท้ายเป็นมะเร็งกระเพาะอาหาร
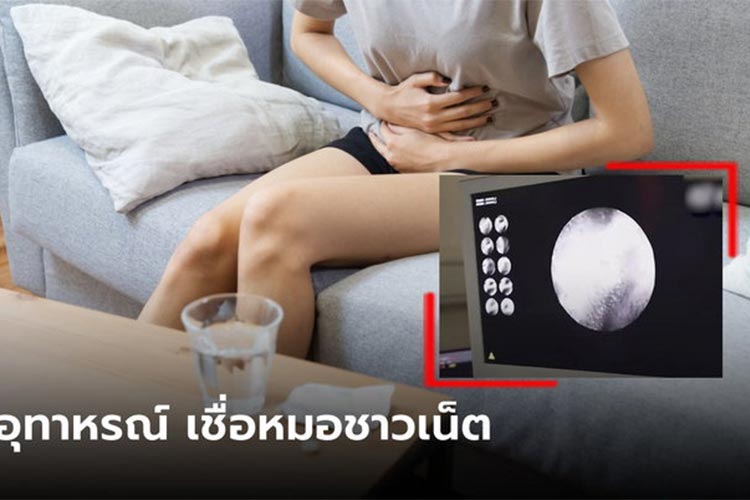
สาวเชื่อหมอในเน็ต “กินน้ำ […]



